[python-파이썬] 안녕하세요 모두의 파이썬입니다 지금까지 정적인 크롤링, 동적인 크롤링(셀레늄 활용)을 해 보았습니다. 뭔가 더 해보고 싶다는 생겼습니다. 크롤링 했던 정보를 기록으로 남기고 싶어졌습니다. 국내 블로그 플랫폼은 크게 네이버 블로그와 티스토리 2종류가 있습니다. 먼저 네이버 블로그에 크롤링 했던 정보를 기록으로 남겨 보겠습니다.
전체 글을 요약하면, 크롤링 한 정보를 셀레늄을 활용하여 네이버 블로그 작성한다
크롤링은 네이버 뉴스에 게시된 것으로 하면서, 키워드는 '삼성전자', 제목이 포함된 기사로 한정한다. 글쓰기에 중점이 맞춰져 있으므로 크롤링은 간략하게 네이버 검색에 삼성전자를 입력하고, 뉴스 탭에 나오는 정보를 크롤링 하는 방식으로 알고리즘을 구현하였다.
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
from selenium import webdriver
from bs4 import BeautifulSoup
import requests
import json
class naver_blog_write():
def __init__(self):
print('hi naver_blog_write')
path = "D:\\chromedriver.exe"
self.driver = webdriver.Chrome(path)
## 로그인은 수동으로 진행, 추후 로그인도 다룰예정
self.driver.get('https://blog.naver.com')
def get_html(self,url):
## 브라우저 호환을 위해서 설정
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '+ \
'(KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'
}
##해당 url에 htlm(정보) 요청에사용 / url은 사용자가 원하는 url
r = requests.get(url, headers=headers)
## 해당 url의 html을 사용자가 활용하기 쉽게 변환
html = BeautifulSoup(r.content, 'html.parser')
## 결과값 전달
return html
def get_news_crawling(self,keyword):
url = 'https://search.naver.com/search.naver?where=news&sm=tab_jum&query=' + keyword
html = self.get_html(url)
l_news = html.find('div',{'class','group_news'})
if l_news != None:
l_news = l_news.find_all('li',{'class','bx'})
for i in l_news:
title_info = i.find('a',{'class','news_tit'})
news_info = i.find_all('a',{'class','info'})[-1]
news_body = i.find('a',{'class','api_txt_lines'})
#print(title_info.get('title'))
#print(news_info.text)
if keyword in title_info.get('title'):
#url, 제목, 본문
title = title_info.get('title')
body = '▣요약 : ' + news_body.text + '\n' + '▣URL : ' + news_info.get('href')
print(title)
print(body)
return title,body
return False
if __name__ == "__main__":
nbw = naver_blog_write()
##로그인은 수동으로 진행
## 크롤링으로 제목과 본문내용 생성
title, body = nbw.get_news_crawling('삼성전자') ## 삼성전자 뉴스 검색 첫페이지
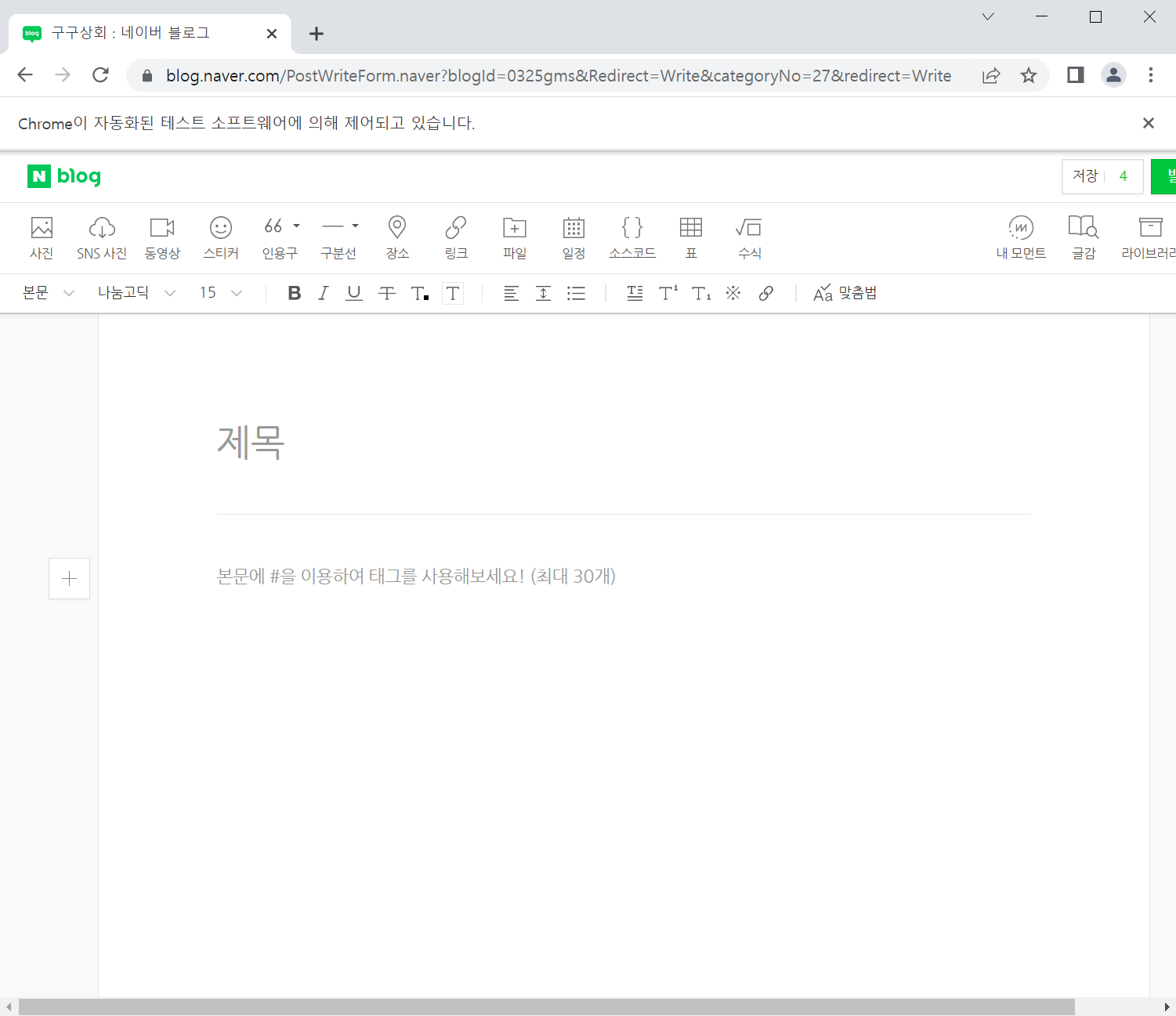
제목과 본문이 원하는 방향으로 출력이 되는 것을 확인하였다 그다음은 크롤링 한 제목과 본문을 입력하기 위해서, 글쓰기 주소를 알아야 한다. 주소는 다음과 같다.. ''https://blog.naver.com/PostWriteForm.naver?blogId=0325gms&Redirect=Write&categoryNo=27&redirect=Write" 여기서 2가지 정보가 있다. 블로그 id는 0325gms이고, 메뉴 코드는 "27"이다 여러분의 정보에 맞게 입력한다. 다음과 같이 글쓰기 주소로 이동한다
## https://blog.naver.com/0325gms에서 노하우에 글작성 (test)
nbw.driver.get('https://blog.naver.com/PostWriteForm.naver?blogId=0325gms&Redirect=Write&categoryNo=27&redirect=Write')
def write_title(self,title):
##글쓰기 란에 '제목' 글자를 찾아서 클릭하려는 목적
title_add = '//span[contains(text(),"제목")]'
##title위치 지정
title_elem = self.driver.find_element_by_xpath(title_add)
##title위치 클릭
title_elem.click()
##동작구현할때 액션체인 사용 (마우스클릭,이동,키입력 등에 사용)
action = ActionChains(self.driver)
##제목을 입력하고 실행
action.send_keys(title).perform()
def write_body(self,body):
##글쓰기 란에 '본문에 #을' 글자를 찾아서 클릭하려는 목적
body_add = '//span[contains(text(),"본문에 #을")]'
##본문위치 지정
body_elem = self.driver.find_element_by_xpath(body_add)
##title위치 클릭
body_elem.click()
##동작구현할때 액션체인 사용 (마우스클릭,이동,키입력 등에 사용)
action = ActionChains(self.driver)
##제목을 입력하고 실행
action.send_keys(body).perform()
## 제목 작성
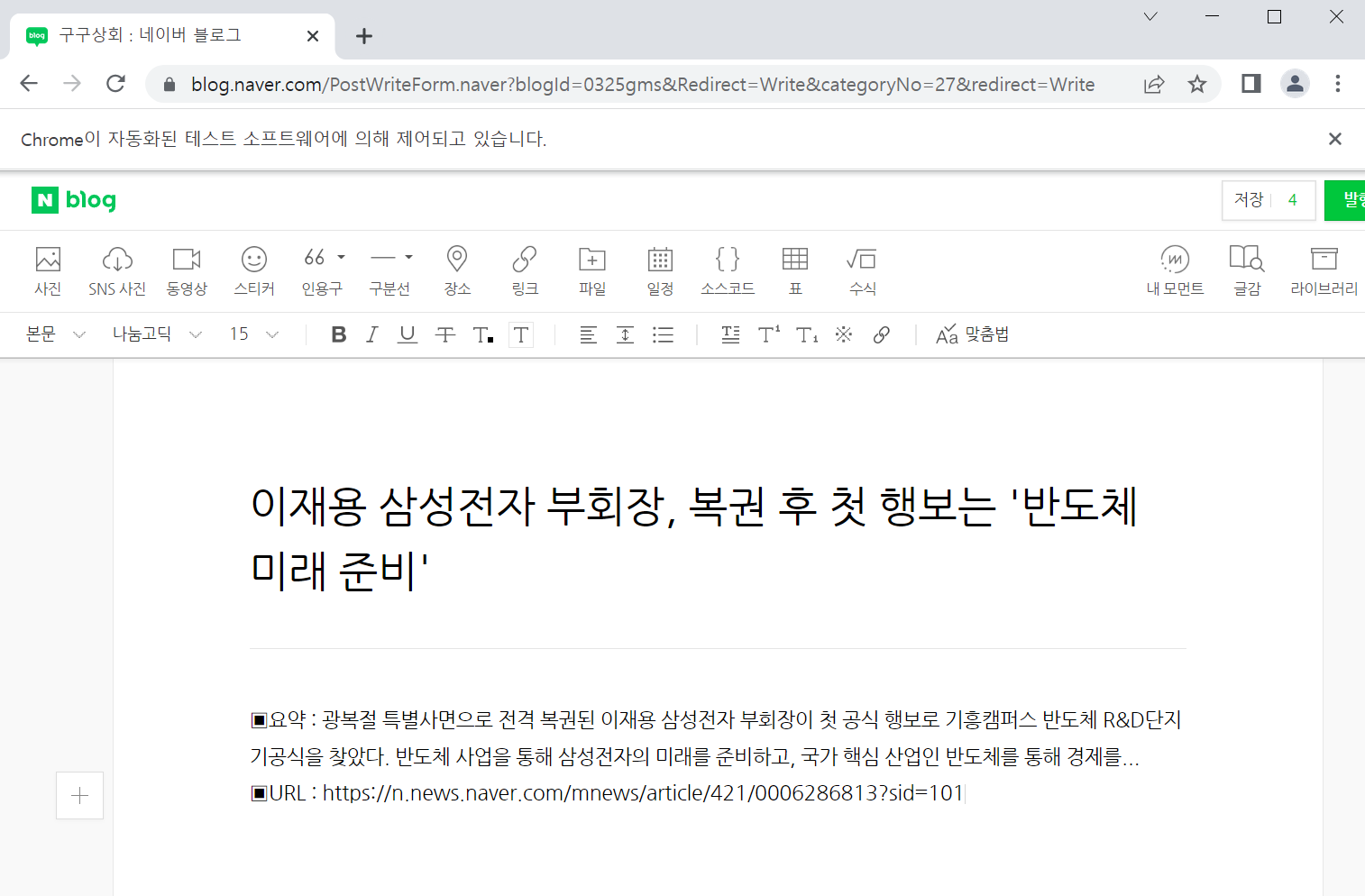
nbw.write_title(title)
## 본문 작성
nbw.write_body(body)
코드를 시행하면, 제목과 본문 내용이 입력 완료된다.
전체 코드는 다음과 같다
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
from selenium import webdriver
from bs4 import BeautifulSoup
import requests
import json
class naver_blog_write():
def __init__(self):
print('hi naver_blog_write')
path = "D:\\chromedriver.exe"
self.driver = webdriver.Chrome(path)
## 로그인은 수동으로 진행, 추후 로그인도 다룰예정
self.driver.get('https://blog.naver.com')
def get_html(self,url):
## 브라우저 호환을 위해서 설정
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '+ \
'(KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'
}
##해당 url에 htlm(정보) 요청에사용 / url은 사용자가 원하는 url
r = requests.get(url, headers=headers)
## 해당 url의 html을 사용자가 활용하기 쉽게 변환
html = BeautifulSoup(r.content, 'html.parser')
## 결과값 전달
return html
def get_news_crawling(self,keyword):
url = 'https://search.naver.com/search.naver?where=news&sm=tab_jum&query=' + keyword
html = self.get_html(url)
l_news = html.find('div',{'class','group_news'})
if l_news != None:
l_news = l_news.find_all('li',{'class','bx'})
for i in l_news:
title_info = i.find('a',{'class','news_tit'})
news_info = i.find_all('a',{'class','info'})[-1]
news_body = i.find('a',{'class','api_txt_lines'})
#print(title_info.get('title'))
#print(news_info.text)
if keyword in title_info.get('title'):
#url, 제목, 본문
title = title_info.get('title')
body = '▣요약 : ' + news_body.text + '\n' + '▣URL : ' + news_info.get('href')
print(title)
print(body)
return title,body
return False
def write_title(self,title):
##글쓰기 란에 '제목' 글자를 찾아서 클릭하려는 목적
title_add = '//span[contains(text(),"제목")]'
##title위치 지정
title_elem = self.driver.find_element_by_xpath(title_add)
##title위치 클릭
title_elem.click()
##동작구현할때 액션체인 사용 (마우스클릭,이동,키입력 등에 사용)
action = ActionChains(self.driver)
##제목을 입력하고 실행
action.send_keys(title).perform()
def write_body(self,body):
##글쓰기 란에 '본문에 #을' 글자를 찾아서 클릭하려는 목적
body_add = '//span[contains(text(),"본문에 #을")]'
##본문위치 지정
body_elem = self.driver.find_element_by_xpath(body_add)
##title위치 클릭
body_elem.click()
##동작구현할때 액션체인 사용 (마우스클릭,이동,키입력 등에 사용)
action = ActionChains(nbw.driver)
##제목을 입력하고 실행
action.send_keys(body).perform()
if __name__ == "__main__":
nbw = naver_blog_write()
##로그인은 수동으로 진행
## 크롤링으로 제목과 본문내용 생성
title, body = nbw.get_news_crawling('삼성전자') ## 삼성전자 뉴스 검색 첫페이지
## https://blog.naver.com/0325gms에서 노하우에 글작성 (test)
nbw.driver.get('https://blog.naver.com/PostWriteForm.naver?blogId=0325gms&Redirect=Write&categoryNo=27&redirect=Write')
## 제목 작성
nbw.write_title(title)
## 본문 작성
nbw.write_body(body)
print('모두의 파이썬')
※좋아요/댓글은 서로를 응원합니다!
'파이썬 > 셀레늄크롤링' 카테고리의 다른 글
| [python-파이썬] SRT 표(티켓) 자동 예매하기 (0) | 2022.06.11 |
|---|