안녕하세요. 모두의 파이썬입니다. 크롤링 예제를 기반으로 파이썬 능력을 발전시키고, 코드에 대한 자신감을 향상시켜 보려 합니다. 크롤링 들어보셨나요? 제가 항상 말씀드리지만, 모른다면 어떻게 해야 하나요? 먼저, 크롬 브라우저를 열고, 알고 싶은 것을 구글에서 검색하고 이해하는 과정을 반복하십시오. 구글에 검색하니 나무위키에서 크롤링을 정의 해놓았습니다. '웹페이지에 있는 데이터를 추출' 이렇게 요약해 보았습니다. 크롤링을 하는 이유는 내가 필요한 데이터를 가져오기 위함입니다. 그리고 그 아래에 'Python이 이 분야의 선두주자'라고 나옵니다. 여러분도 저도 선택을 참 잘했습니다.

다다익선이라는 말이 있습니다. 많이 검색해 보시고 찾아보시면, 누구보다도 많이 아시게 될 것입니다. 그것은 여러분의 숙제로 남기고, 실행력이 최우선인 '모두의 파이썬'은 본론으로 들어가겠습니다
전체 글을 요약하면, 네이버 증권에서 '내가 필요한 주식정보를 가져온다' (크롤링 - crawling)입니다
우선 내가 필요한 정보가 있는 네이버 증권으로 한번 떠나보실 까요? 웹주소는 https://finance.naver.com 입니다. 정말 많이 접속해 보아서, 주소를 외우고 있습니다. 그리고 좋은 정보를 제공해 준 네이버 증권에 감사를 표합니다.
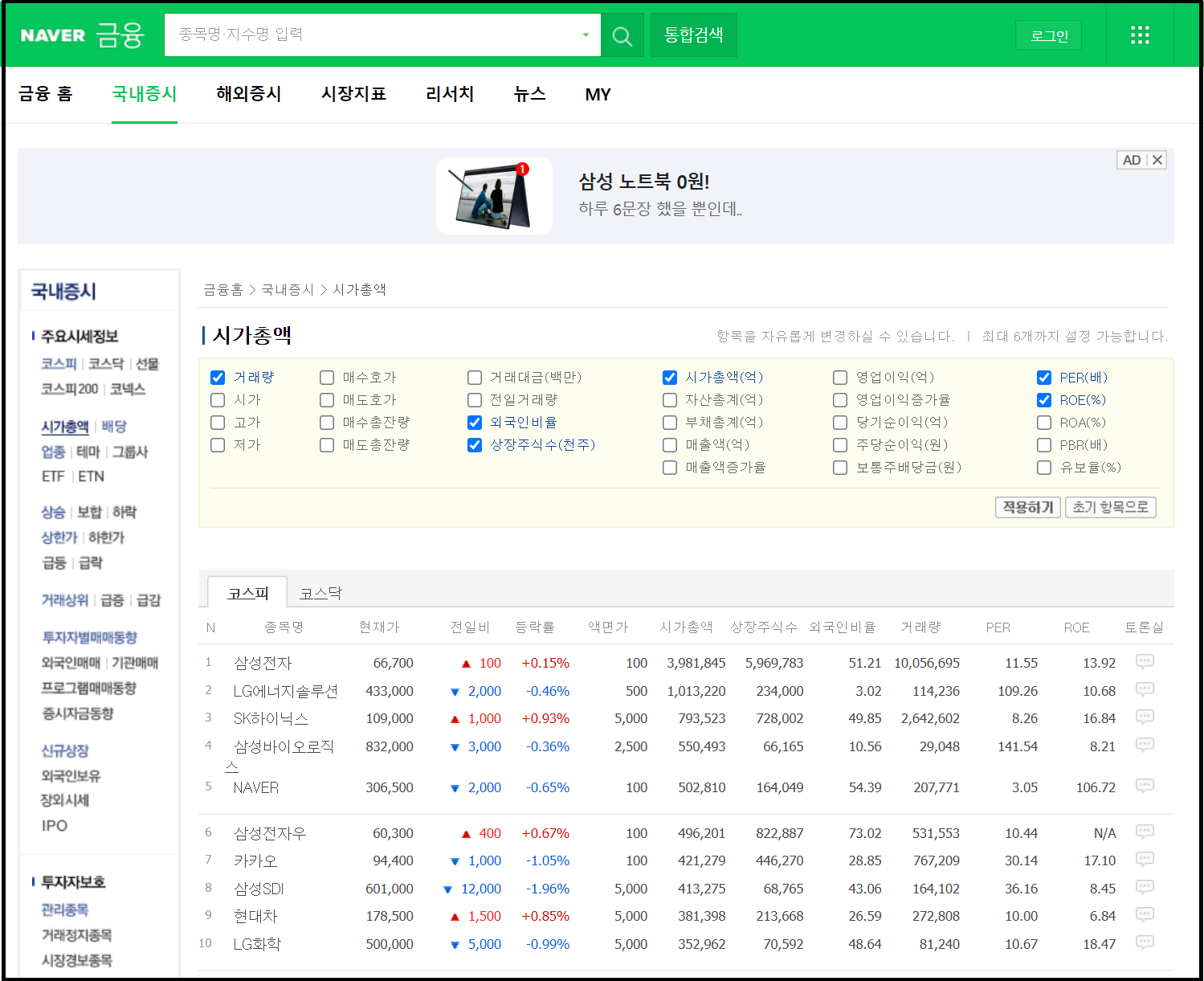
위에 네이버 증권 메인 페이지는 친숙하기 위해 소개를 드린 것이고, 제가 필요한 정보의 주소는 '메인화면 > 국내 증시 > 시가총액'순서로 가셔서 주식의 시가총액 정보가 화면에 나와야 합니다. 상세 방법은 아래 그림 참조하세요
시가총액을 누르면 제가 원하는 페이지가 나옵니다. 페이지주소는 https://finance.naver.com/sise/sise_market_sum.naver 입니다. 기본 화면은 '코스피'이고 '코스닥'도 클릭하시면, 페이지 주소가 바뀌는 걸 확인할 수 있습니다. '코스피 주소'는 https://finance.naver.com/sise/sise_market_sum.naver?sosok=0 '코스닥 주소'는 https://finance.naver.com/sise/sise_market_sum.naver?sosok=1 을 확인하셨나요? ~sosok=까지는 동일하고 뒤에 0/1로 구분이 되는 것을 확인할 수 있습니다. 지금부터 규칙성을 기반으로 진행하려 합니다. 국내 주식 수가 3300여 종목이기 때문에 여러 페이지로 이루어져 있습니다. 그래서 페이지도 규칙적으로 구성이 되어야만 크롤링을 에러 없이 진행할 수 있습니다.
모두의 파이썬이 세운 코딩 철학이 있습니다. '최소한의 반복성으로 코드를 완성하라'입니다. '여러 종목을 크롤링 하기 전에 한 종목을 크롤링 하는 것을 완성하라'입니다. 반복성을 찾아내고 구현하는 것이 코딩의 목적입니다. 주피터 노트북에서 간단히 구현해 보겠습니다.
##HTTP를 호출하는 프로그램을 작성할 때 주로 사용한다
import requests
## html의 내용을 사용자가 활용하기 쉽게 하기위해 사용한다
from bs4 import BeautifulSoup
##원하는 정보가 있는 주소
url = 'https://finance.naver.com/sise/sise_market_sum.naver?sosok=0'
## 브라우저 호환을 위해서 설정
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '+ \
'(KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'
}
##해당 url에 htlm(정보) 요청에사용 / url은 사용자가 원하는 url
r = requests.get(url, headers=headers, verify=True)
## 해당 url의 html을 사용자가 활용하기 쉽게 변환
html = BeautifulSoup(r.text, 'html.parser')
##html에 주식정보가 있는 tag이며 find_all이기 때문에 리스트형태
tmp = html.find_all('tr', {'onmouseover': "mouseOver(this)"})
##리스트 형태이기 때문에 for문 사용 (for는 반복문 : 파이썬기초)
for i in tmp:
##주식정보가 있는 태그가 'td'이면서 list의 첫번째
tmp2 = i.find_all('td')[1]
##주식명이 tag 'a'에 존재
name = tmp2.find('a').text
##주식가격이 i의 tag 'td'의 list 3번째에 존재
price = int(i.find_all('td')[2].text.replace(',',''))
print([name,price])
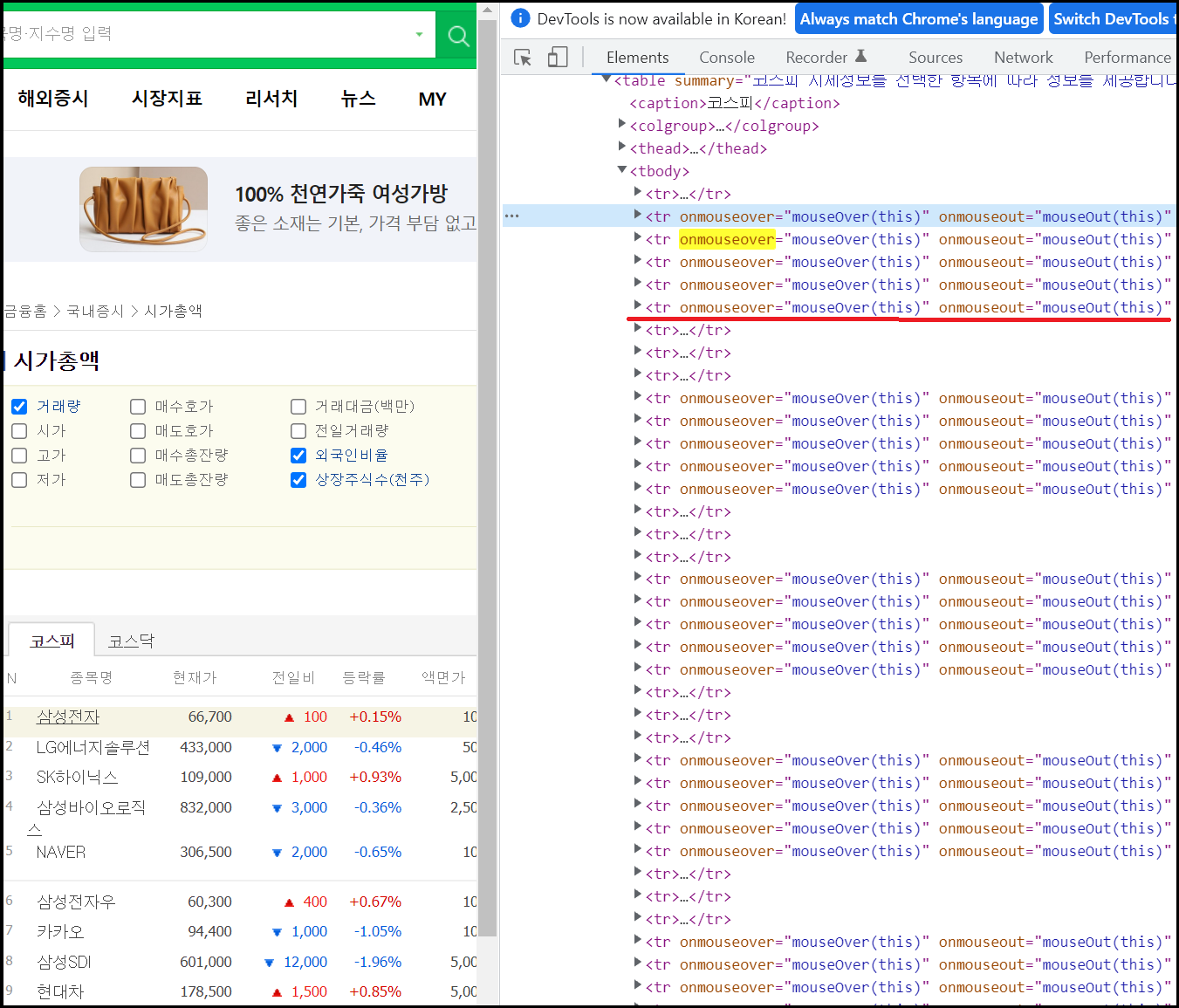
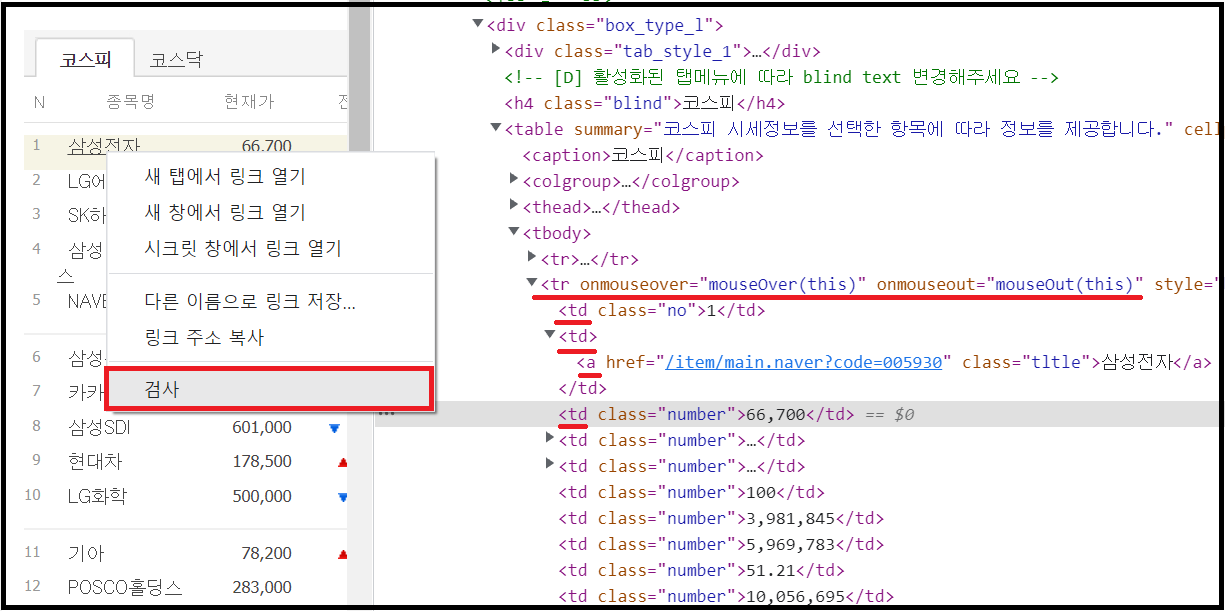
종목명/현재가 두 가지만 얻어보겠습니다. 'tag'정보를 분석하기 위해서는 page에 커서를 두고 우 클릭한 뒤 '검사'를 클립 합니다. 종목명은 'tr/onmouseover/mouseOver(this)'에서 두 번째'td' / 첫 번째'a'입니다. 첫 번째 'tag'정보만 얻을 때는 find_all 대신 find를 사용합니다. tmp2 = i.find_all('td')[1] / name = tmp2.find('a').text가 되는 것입니다. 그리고 가격은 세 번째'td'를 코드로 바꾸면 price = int(i.find_all('td')[2].text.replace(',',''))입니다. 가격은 int 형태이기 때문에 가격에 포함된 3자리 구분제/콤마를 제거하고, string을 int로 변환하여 price 변수에 입력합니다.
1탄에서는 네이버 증권에서 종목명/주식가격 가져오는 크롤링 예제를 구현하였습니다. 2탄에서는 전체 페이지와 코스닥까지 구현하겠습니다. 1탄에서 배운 내용이 90%입니다. 전체 페이지는 페이지 개수만큼 for 문을 수행하면 되며, 코스닥은 'sosok=0'을 'sosok=1'로 변환하면 전체 코드가 완성됩니다.
print('모두의 파이썬')
※좋아요/댓글은 서로를 응원합니다!
'파이썬 > 크롤링' 카테고리의 다른 글
| [python-파이썬] 10 유튜브에서 동영상 정보 크롤링 (crawling) - 1탄 (0) | 2022.04.21 |
|---|---|
| [python-파이썬] 8 네이버에서 블로그 정보 크롤링 (crawling) - 1탄 (0) | 2022.04.21 |
| [python-파이썬] 7 네이버에서 종목뉴스 크롤링 (crawling) - 2탄 (1) | 2022.04.21 |
| [python-파이썬] 6 네이버에서 종목뉴스 크롤링 (crawling) - 1탄 (1) | 2022.04.21 |
| [python-파이썬] 5 네이버 증권에서 주식정보 크롤링 (crawling) - 2탄 (0) | 2022.04.19 |