판다스연산을 시작하기 전에
계속 반복해야 하는것이 있음
판다스는 패키지를 활용하는 것이며
가장 기본적인 형태는 수 없이 반복해도
지나치지 않음
import pandas as pd
df = pd.DataFrame()
print(df)-결과 (드래그로 확인가능)
Empty DataFrame
Columns: []
Index: []
비어있는 데이터프레임을 선언했고
결과는 인덱스와 컬럼이 출력됨
비어있는 데이터프레임이기 때문에
값은 출력되지 않음
주피터 노트북에서는 print()로
출력을 할 수도 있지만
변수 자체를 코딩할 수 있는 Cells에
입력후 출력할 수도 있음
사용자가 시각적으로 편한 방법으로선택가능함
#출력1 print로 출력
import pandas as pd
df = pd.DataFrame(columns = ['col1','col2','col3'],index = ['index1','index2','index3'])
df['col1'] = [1,4,7]
df['col2'] = [2,5,8]
df['col3'] = [3,6,9]
print(df)-결과 (이미지 출력)

#출력2 직집출력
import pandas as pd
df = pd.DataFrame(columns = ['col1','col2','col3'],index = ['index1','index2','index3'])
df['col1'] = [1,4,7]
df['col2'] = [2,5,8]
df['col3'] = [3,6,9]
df-결과 (이미지 출력)

판다스의 기본 입력은 다양함
import pandas as pd
df = pd.DataFrame(columns = ['col1','col2','col3'],index = ['index1','index2','index3'])
df['col1'] = [1,4,7]
df['col2'] = [2,5,8]
df['col3'] = [3,6,9]
print('df')
print(df)
print('-------------')
data = [[1,2,3],[4,5,6],[7,8,9]]
df2 = pd.DataFrame(columns = ['col1','col2','col3'],index = ['index1','index2','index3'],data = data)
print('df2')
print(df2)-결과 (이미지 출력)

data = [[1,2,3],[4,5,6],[7,8,9]] 를 살펴보면
index기준으로 입력되는 것을 볼수 있음
결과는 동일하며 사용자가 원하는 방식대로
사용하되 DataFrame 함수 내부에 columns와 index
그리고 data는 알아야 함
import pandas as pd
data = [[1,2,3],[4,5,6],[7,8,9]]
df = pd.DataFrame(data = data)
print(df)-결과 (이미지 출력)

columns index data 요소가 있음
이중에 columns와 index를 입력하지 않으면
기본적으로 0부터 시작하여 정의됨
그러면 data가 입력되지 않으면 뭐다?
import pandas as pd
df = pd.DataFrame(columns = ['col1','col2','col3'],index = ['index1','index2','index3'])
print(df)-결과 (이미지 출력)

data가 잆력되지 않으면, NaN으로 결측치라고 불리며
누락된 숫자 데이터를 의미함 우선 여기까지만 알아두고 결측치편에서 심도있게 예정임
pandas사칙연산은 python기초에서 배운
사칙연산과 비슷함
다양한 예시도 살펴 볼수 있지만
다른 사람이 잘 만들어 놓은 함수가
활용도가 큼
DataFrame.add(other, axis='columns', level=None, fill_value=None)
의 함수가 존재함 add 함수임
other는 다른 dataframe형태 될 수 있음
df = df + df2와 df = df.add(df2) 와 동일한 결과값임
df3 = df.add(df2,fill_value =10) 로 하면 df와 df2 둘중
한 군데에 해당하여 NaN을 10으로 바꿔서 연산을 진행함
해당 columns과 index에 모두 NaN이면 결과도 NaN이됨
import pandas as pd
data = [[1,2,3],[4,5,6],[7,8,9]]
df = pd.DataFrame(columns = ['col1','col2','col3'],index = ['index1','index2','index3'],data = data)
print(df)
print('\n------------------\n')
df2 = df.add(1, fill_value = 10)
print(df2)
print('\n------------------\n')
df3 = pd.DataFrame(columns = ['col1','col2','col3'],index = ['index1','index2','index3'])
print(df3)
print('\n------------------\n')
df4 = df3.add(1, fill_value = 10)
print(df4)
print('\n------------------\n')-결과 (이미지 출력)

기본적으로 덧셈은 columns와 index의 위치에
맞게 각각 연산이 이루어짐
add(1)은 전체 columns과 index에 동일하게
적용됨
그리고 fill_value = 10은 NaN에 해당되는 위치에
10을 채운다는 의미임
그래서 add(1, fill_value = 10)을 하면 NaN에 10을채우고 1을 모두 더해줌
import pandas as pd
data = [[1,2,3],[4,5,6],[7,8,9]]
df = pd.DataFrame(columns = ['col1','col2','col3'],index = ['index1','index2','index3'],data = data)
print(df)
print('\n------------------\n')
data2 = [[1],[4],[7]]
df2 = pd.DataFrame(columns = ['col1'],index = ['index1','index2','index3'],data = data2)
print(df2)
print('\n------------------\n')
df3 = df.add(df2)
print(df3)
print('\n------------------\n')
df4 = df.add(df2, fill_value = 10)
print(df4)
print('\n------------------\n')-결과 (이미지 출력)

특징적인 것은 NaN과 숫자의 연산 결과는
NaN이 됨그래서 fill_value = 10이 수행되면 df와 df2연산전 df2의 NaN에 10이초기화 입력되고 df의 columns와 index에해당되는 값들과 연산이 완료됨
DataFrame.sub(other, axis='columns', level=None, fill_value=None)
의 함수가 존재함 sub함수임 빼기 함수이며 전체 틀은 add와 유사함
import pandas as pd
data = [[1,2,3],[4,5,6],[7,8,9]]
df = pd.DataFrame(columns = ['col1','col2','col3'],index = ['index1','index2','index3'],data = data)
print(df)
print('\n------------------\n')
data2 = [[1],[4],[7]]
df2 = pd.DataFrame(columns = ['col1'],index = ['index1','index2','index3'],data = data2)
print(df2)
print('\n------------------\n')
df3 = df.sub(df2)
print(df3)
print('\n------------------\n')
df4 = df.sub(df2, fill_value = 10)
print(df4)
print('\n------------------\n')-결과 (이미지 출력)

DataFrame.mul(other, axis='columns', level=None, fill_value=None)
의 함수가 존재함 mul함수임 곱하기 함수이며 전체 틀은 add와 유사함
import pandas as pd
data = [[1,2,3],[4,5,6],[7,8,9]]
df = pd.DataFrame(columns = ['col1','col2','col3'],index = ['index1','index2','index3'],data = data)
print(df)
print('\n------------------\n')
data2 = [[1],[4],[7]]
df2 = pd.DataFrame(columns = ['col1'],index = ['index1','index2','index3'],data = data2)
print(df2)
print('\n------------------\n')
df3 = df.mul(df2)
print(df3)
print('\n------------------\n')
df4 = df.mul(df2, fill_value = 10)
print(df4)
print('\n------------------\n')-결과 (이미지 출력)

DataFrame.div(other, axis='columns', level=None, fill_value=None)
의 함수가 존재함 div함수임 나누기 함수이며 전체 틀은 add와 유사함
import pandas as pd
data = [[1,2,3],[4,5,6],[7,8,9]]
df = pd.DataFrame(columns = ['col1','col2','col3'],index = ['index1','index2','index3'],data = data)
print(df)
print('\n------------------\n')
data2 = [[1],[4],[7]]
df2 = pd.DataFrame(columns = ['col1'],index = ['index1','index2','index3'],data = data2)
print(df2)
print('\n------------------\n')
df3 = df.div(df2)
print(df3)
print('\n------------------\n')
df4 = df.div(df2, fill_value = 10)
print(df4)
print('\n------------------\n')-결과 (이미지 출력)
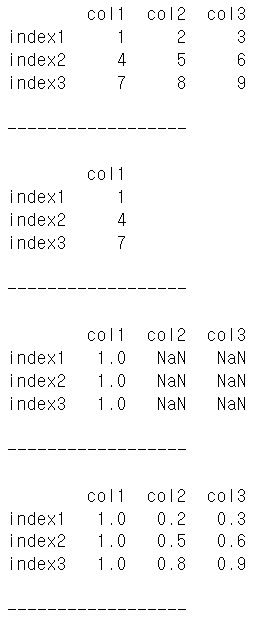
판다스의 사칙연산이
일반 사칙연산과 유사한 것을 확인함
NaN이 포함되어 있으면 연산이 안되고
일괄적 fill_value로 입력이 되며
입력은 float형임
태그
-------------------------------------------------------------
#python, #파이썬, #anaconda, #아나콘다, #기초, #클래스, #class, #import, #selenium, #셀레늄, #자동, #교육, #코딩교육, #coding, #chatgpt, #챗GPT, #로봇,

'파이썬판다스 따라하기 > 3판다스연산' 카테고리의 다른 글
| #판다스연산4편 - 판다스 diff pct_change expending rolling groupby ewm 함수 (31) | 2023.06.01 |
|---|---|
| #판다스연산3편 - 판다스 round sum prod abs transpose rank 함수 (30) | 2023.05.28 |
| #판다스연산2편 - 판다스 mod pow dot함수 (21) | 2023.05.27 |